Kubernetes ControllerManager 源码学习
01 January 2020
Kubernetes 版本:1.15.7
服务的创建
入口文件:cmd/kube-controller-manager/app/controllermanager.go,启动的主要逻辑都在该文件的 Run 方法中。
- 如果开启了 –leader-elect 参数,添加对应的健康检查,该功能是用于启动多个 kube-controller-manager 实例时,选举出一个领导者负责执行控制循环
- 启动安全和非安全的 HTTP 服务,提供了健康检查、性能分析、查看配置的接口
- run 闭包函数,如果开启了 –leader-elect,会在 leaderelection.RunOrDie 中被调用,否则直接调用
- 准备 rootClientBuilder 和 clientBuilder
- 创建服务的主要配置 app.ControllerContext
- 创建 Informer 工厂
- InformerFactory:用于常规 API 资源对象的控制器
- GenericInformerFactory:用于 garbagecollector 和 resourcequota 控制器
- 创建 RESTMapper
- 创建 CloudProvider
- 创建 Informer 工厂
- 创建 serviceAccountTokenController,并启动
- 创建其他的 Controller,并启动
- 启动 Informer:InformerFactory.Start(app.ControllerContext.Stop)、GenericInformerFactory.Start(app.ControllerContext.Stop)
API 资源对象的控制器的创建和启动
以 DeploymentController 为例,入口函数为:
func startDeploymentController(ctx ControllerContext) (http.Handler, bool, error) {
// 判断 API 资源对象是否可用
if !ctx.AvailableResources[schema.GroupVersionResource{Group: "apps", Version: "v1", Resource: "deployments"}] {
return nil, false, nil
}
// 创建对应的 informer 和 client
dc, err := deployment.NewDeploymentController(
ctx.InformerFactory.Apps().V1().Deployments(),
ctx.InformerFactory.Apps().V1().ReplicaSets(),
ctx.InformerFactory.Core().V1().Pods(),
ctx.ClientBuilder.ClientOrDie("deployment-controller"),
)
if err != nil {
return nil, true, fmt.Errorf("error creating Deployment controller: %v", err)
}
go dc.Run(int(ctx.ComponentConfig.DeploymentController.ConcurrentDeploymentSyncs), ctx.Stop)
return nil, true, nil
}
Informer 工厂
k8s.io/client-go/informers.SharedInformerFactory 接口定义了用于创建各类 API 资源对象 informer 的方法,ctx.InformerFactory.Apps().V1().Deployments() 会创建 k8s.io/client-go/informers/apps/v1.deploymentInformer,该类型用于创建最终的 informer 和 lister。
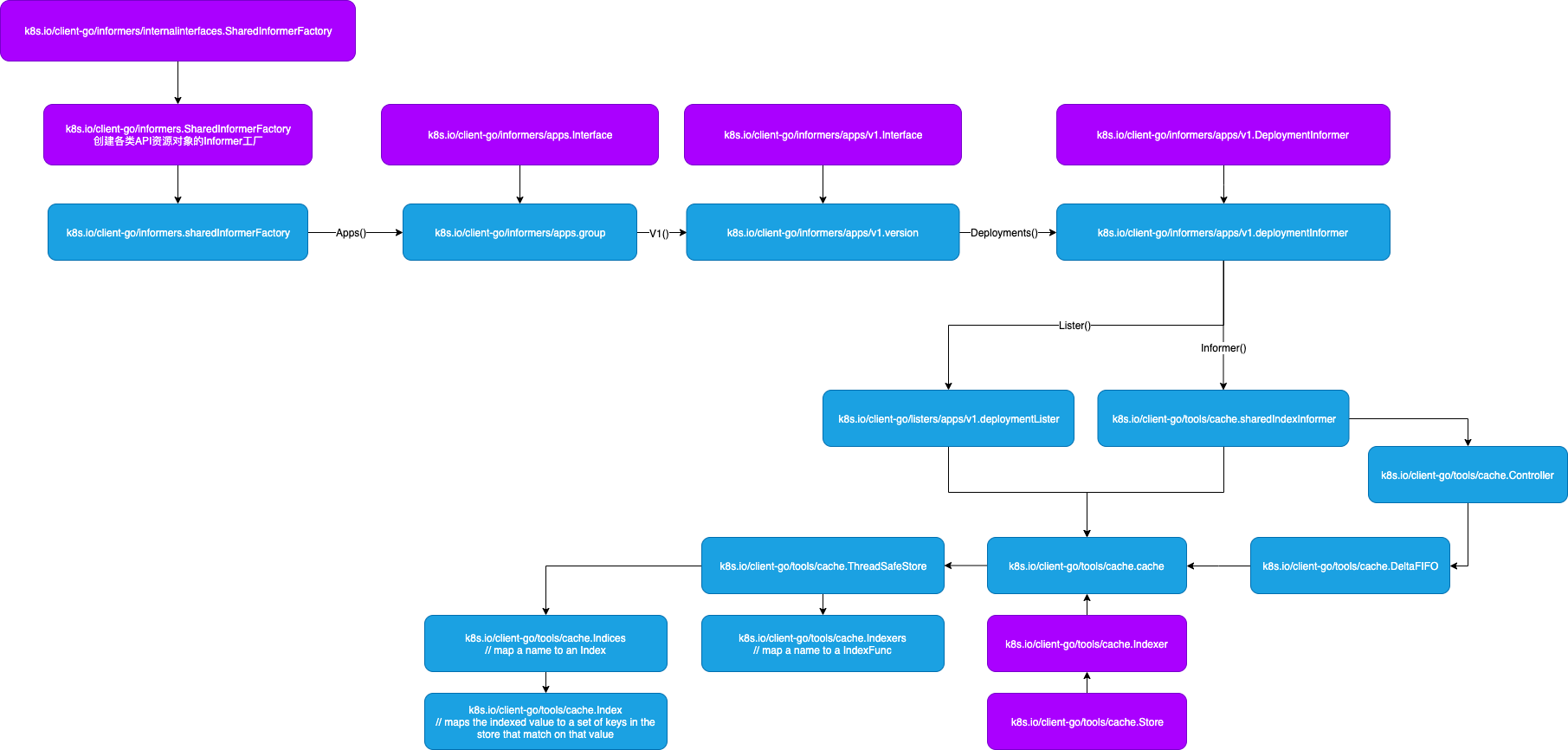
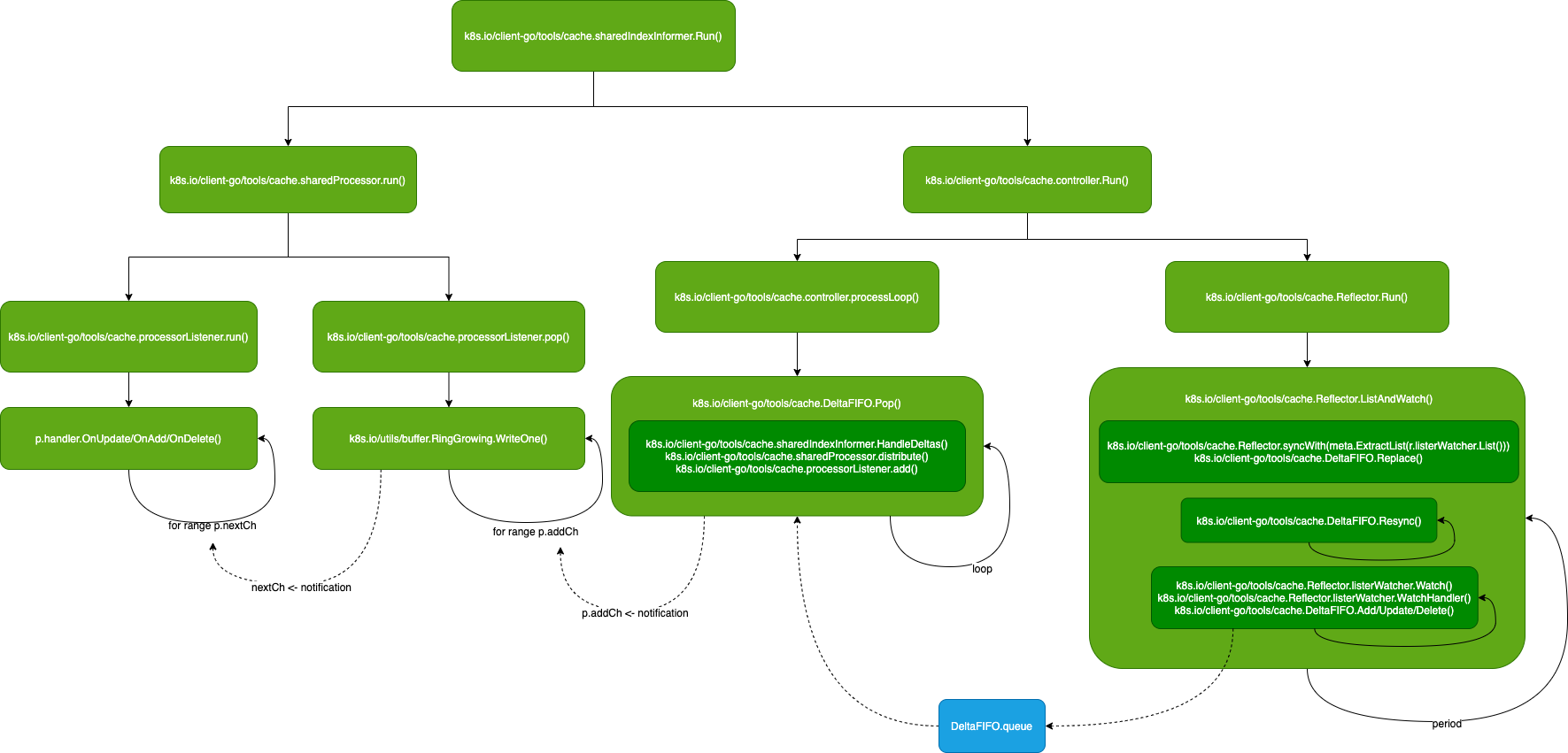
Informer 工作机制
k8s.io/client-go/tools/cache.sharedIndexInformer.Run() 会启动2个工作循环:
- k8s.io/client-go/tools/cache.Controller.Run():负责初始化缓存队列,并监听 API 资源对象的更新,如果收到更新消息,则入队
- k8s.io/client-go/tools/cache.sharedProcessor.run():负责从缓存队列里出队消息,执行相应的 API 资源对象控制器注册的回调函数
DeploymentController 的创建
// NewDeploymentController creates a new DeploymentController.
func NewDeploymentController(dInformer appsinformers.DeploymentInformer, rsInformer appsinformers.ReplicaSetInformer, podInformer coreinformers.PodInformer, client clientset.Interface) (*DeploymentController, error) {
// 记录发生的事件
eventBroadcaster := record.NewBroadcaster()
eventBroadcaster.StartLogging(klog.Infof)
eventBroadcaster.StartRecordingToSink(&v1core.EventSinkImpl{Interface: client.CoreV1().Events("")})
if client != nil && client.CoreV1().RESTClient().GetRateLimiter() != nil {
if err := metrics.RegisterMetricAndTrackRateLimiterUsage("deployment_controller", client.CoreV1().RESTClient().GetRateLimiter()); err != nil {
return nil, err
}
}
dc := &DeploymentController{
client: client,
eventRecorder: eventBroadcaster.NewRecorder(scheme.Scheme, v1.EventSource{Component: "deployment-controller"}),
queue: workqueue.NewNamedRateLimitingQueue(workqueue.DefaultControllerRateLimiter(), "deployment"),
}
dc.rsControl = controller.RealRSControl{
KubeClient: client,
Recorder: dc.eventRecorder,
}
// 注册事件处理回调
dInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: dc.addDeployment,
UpdateFunc: dc.updateDeployment,
// This will enter the sync loop and no-op, because the deployment has been deleted from the store.
DeleteFunc: dc.deleteDeployment,
})
rsInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: dc.addReplicaSet,
UpdateFunc: dc.updateReplicaSet,
DeleteFunc: dc.deleteReplicaSet,
})
podInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
DeleteFunc: dc.deletePod,
})
dc.syncHandler = dc.syncDeployment
dc.enqueueDeployment = dc.enqueue
dc.dLister = dInformer.Lister()
dc.rsLister = rsInformer.Lister()
dc.podLister = podInformer.Lister()
dc.dListerSynced = dInformer.Informer().HasSynced
dc.rsListerSynced = rsInformer.Informer().HasSynced
dc.podListerSynced = podInformer.Informer().HasSynced
return dc, nil
}
DeploymentController 的运行
// Run begins watching and syncing.
func (dc *DeploymentController) Run(workers int, stopCh <-chan struct{}) {
defer utilruntime.HandleCrash()
defer dc.queue.ShutDown()
klog.Infof("Starting deployment controller")
defer klog.Infof("Shutting down deployment controller")
// 等待资源对象至少被同步一次
if !controller.WaitForCacheSync("deployment", stopCh, dc.dListerSynced, dc.rsListerSynced, dc.podListerSynced) {
return
}
// 启动指定的worker数量
for i := 0; i < workers; i++ {
go wait.Until(dc.worker, time.Second, stopCh)
}
<-stopCh
}
// worker runs a worker thread that just dequeues items, processes them, and marks them done.
// It enforces that the syncHandler is never invoked concurrently with the same key.
func (dc *DeploymentController) worker() {
for dc.processNextWorkItem() {
}
}
// 从队列里取出需要处理的 Deployment key
func (dc *DeploymentController) processNextWorkItem() bool {
key, quit := dc.queue.Get()
if quit {
return false
}
defer dc.queue.Done(key)
err := dc.syncHandler(key.(string))
dc.handleErr(err, key)
return true
}
DeploymentController 向 Informer 注册的回调函数会被调用,并把发生更新的 Deployment 对象的 Key 写入到 dc.queue 队列中。
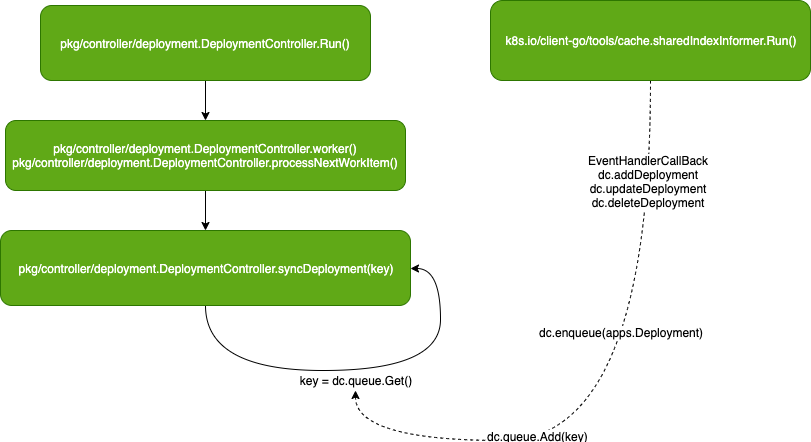
DeploymentController 对资源对象主要的处理逻辑
从 dc.queue 出队的 key,会调用 syncDeployment 方法:
// syncDeployment will sync the deployment with the given key.
// This function is not meant to be invoked concurrently with the same key.
func (dc *DeploymentController) syncDeployment(key string) error {
// key 是发生变更的 Deployment 对象的 key,也包括 kube-controller-manager 启动时,从 API Server 获取到的全量 Deployment 的 key
startTime := time.Now()
klog.V(4).Infof("Started syncing deployment %q (%v)", key, startTime)
defer func() {
klog.V(4).Infof("Finished syncing deployment %q (%v)", key, time.Since(startTime))
}()
namespace, name, err := cache.SplitMetaNamespaceKey(key)
if err != nil {
return err
}
// 调用接口获取 Deployment 对象
deployment, err := dc.dLister.Deployments(namespace).Get(name)
if errors.IsNotFound(err) {
klog.V(2).Infof("Deployment %v has been deleted", key)
return nil
}
if err != nil {
return err
}
// Deep-copy otherwise we are mutating our cache.
// TODO: Deep-copy only when needed.
d := deployment.DeepCopy()
everything := metav1.LabelSelector{}
if reflect.DeepEqual(d.Spec.Selector, &everything) {
dc.eventRecorder.Eventf(d, v1.EventTypeWarning, "SelectingAll", "This deployment is selecting all pods. A non-empty selector is required.")
if d.Status.ObservedGeneration < d.Generation {
d.Status.ObservedGeneration = d.Generation
dc.client.AppsV1().Deployments(d.Namespace).UpdateStatus(d)
}
return nil
}
// 获取 Deployment 拥有的 ReplicaSets
// List ReplicaSets owned by this Deployment, while reconciling ControllerRef
// through adoption/orphaning.
rsList, err := dc.getReplicaSetsForDeployment(d)
if err != nil {
return err
}
// 获取 Deployment 拥有的 Pod
// List all Pods owned by this Deployment, grouped by their ReplicaSet.
// Current uses of the podMap are:
//
// * check if a Pod is labeled correctly with the pod-template-hash label.
// * check that no old Pods are running in the middle of Recreate Deployments.
podMap, err := dc.getPodMapForDeployment(d, rsList)
if err != nil {
return err
}
// Deployment 被删除了
if d.DeletionTimestamp != nil {
// 更新 Deployment 的状态
return dc.syncStatusOnly(d, rsList)
}
// Update deployment conditions with an Unknown condition when pausing/resuming
// a deployment. In this way, we can be sure that we won't timeout when a user
// resumes a Deployment with a set progressDeadlineSeconds.
if err = dc.checkPausedConditions(d); err != nil {
return err
}
if d.Spec.Paused {
// Deployment 被挂起了,删除所有存活的 ReplicaSets
return dc.sync(d, rsList)
}
// rollback is not re-entrant in case the underlying replica sets are updated with a new
// revision so we should ensure that we won't proceed to update replica sets until we
// make sure that the deployment has cleaned up its rollback spec in subsequent enqueues.
// 执行回滚操作
if getRollbackTo(d) != nil {
return dc.rollback(d, rsList)
}
// 执行扩容,缩容操作
scalingEvent, err := dc.isScalingEvent(d, rsList)
if err != nil {
return err
}
if scalingEvent {
return dc.sync(d, rsList)
}
// 执行 Pod 的更新
switch d.Spec.Strategy.Type {
case apps.RecreateDeploymentStrategyType:
return dc.rolloutRecreate(d, rsList, podMap)
case apps.RollingUpdateDeploymentStrategyType:
return dc.rolloutRolling(d, rsList)
}
return fmt.Errorf("unexpected deployment strategy type: %s", d.Spec.Strategy.Type)
}