理解Linux操作系统——file system、I/O subsystem、Network subsystem
学习自《Linux性能分析》
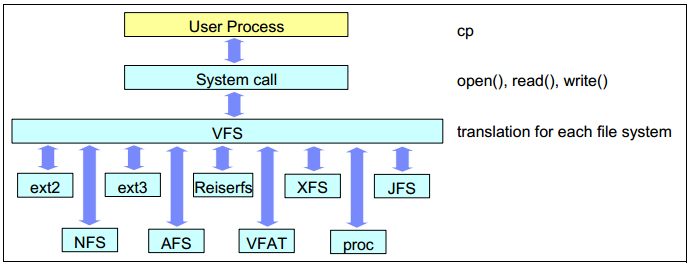
虚拟文件系统
Virtual Files System (VFS)是位于用户进程和各类Linux文件系统实现之间的抽象接口层。
Journaling
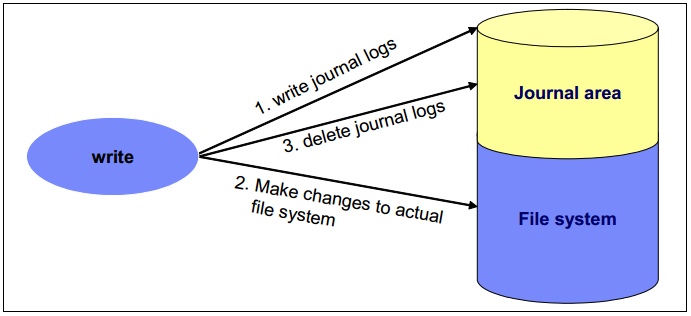
在一个non-journaling文件系统中,当进行写操作时,会先修改文件系统的metadata,然后才写用户数据。这样的操作很可能导致数据不完整。如果系统突然崩溃而刚好写操作正在修改文件系统的metadata,文件系统的一致性可能被破坏了。fsck命令通过检查所有的元数据并修复一致性在下次重启时。但是,如果文件系统的卷过大,那么将会花费很多时间来完成。
Journaling文件系统解决了这一问题:先写journal log,再写用户数据到文件系统中,但是这样就存在写性能问题了。
Ext2
ext2是ext3的前身,一个快速、简单的文件系统,没有journaling功能。
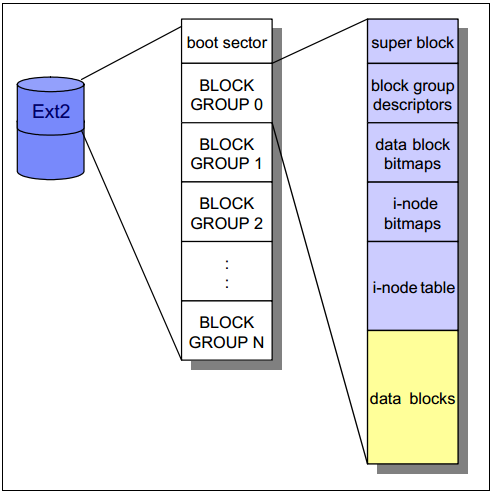
如下图所示,ext2文件系统从boot sector之后开始,跟随者许多block groups。将整个文件系统划分为多个block group有助于性能的提高,因为i-node和data blocks的存储位置比较贴近,那么seek time就能够降低。
- Super block: 文件系统的信息,每一个block group都有一份拷贝。
- Block group descriptor: block group的信息。
- Data block bitmaps: 用于空闲data block的管理。
- i-node bitmaps: 用于空闲i-node的管理。
- i-node tables: i-node表都存储在这里,每一个文件都有相应的i-node表,用于存储文件的元数据:file mode, uid, gid, atime, ctime, mtime, dtime, pointer to data block。
- Data blocks: 存储用户数据
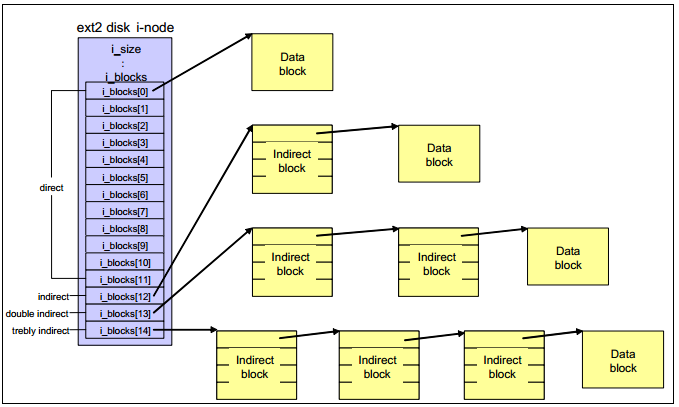
例如查找/var/log/messages文件,内核会解析文件路径,先找到目录入口/的i-node信息,得到/var的i-node,一直找到/var/log/messages的i-node。内核使用object cache(例如directory entry cache)或i-node cache来加速查找相应的i-node。
内核通过i-node中的pointer to data block取出进程请求的data block。
对于不同的文件系统,文件系统结构和文件访问操作是不同的,这使得文件系统之间各有特色。
Ext3
基本的文件系统结构和ext2相似,主要的不同在于journaling的支持。
- 可用性:ext3总是一致性地写数据到磁盘,所以当不正常的关机(断电或系统崩溃),系统重启时不需要花费时间检查数据的完整性。
- 数据完整性:通过指定journaling mode
data=journal在mount时,所有的数据,包括file data和meta data都是journaled。 - 速度:通过指定journaling mode
data=writeback,来提高写性能,但会影响完整性。 - 灵活性:从ext2更新到ext3是很简单的,不需要重新格式化。并且ext3文件系统还可以挂载为ext2文件系统使用。
Mode of journaling
- journal: 最高级别的数据一致性保证,所有的数据都将journaled,但会牺牲写性能。
- writeback: 不做任何数据journaling,这可能导致最近修改的文件在非正常重启时被毁坏,当写性能很好。
- ordered: 只对metadata journaling,写磁盘时,会先写data block,再写metadata。性能介于journal和writeback之间,当发生非正常重启时,可能会出现文件的部分data block被更新。
ReiserFS
fast journaling 文件系统,优化磁盘空间利用率和快速crash recovery。商业软件。
Journal File System
64bit文件系统,支持超大文件和分区。
XFS
高性能的journaling文件系统,特性类似于JFS。
查看挂载点文件系统类型:sudo df -hT。
磁盘I/O子系统
I/O子系统架构
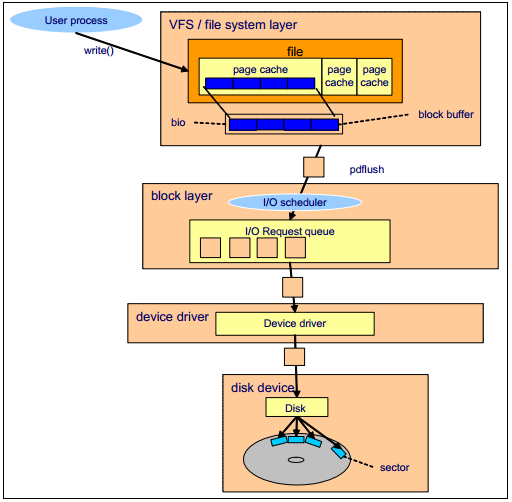
以一个写操作为例,假设file data已经被读取,并且在page cache中:
- 进程调用write()
- 内核更新映射file的page cache
- pdflush内核线程负责将page cache冲刷到磁盘
- 文件系统层将每一个block buffer放到一个bio结构中,然后提交些请求到快设备层
- 块设备层执行I/O elevator操作,将请求放入I/O请求队列中
- 块设备驱动例如SCSI或者其他特定的驱动将负责写操作
- 磁盘设备固件执行硬件操作,如寻道、旋转、数据传输到盘片的扇区
Cache
内存架构:

局部性原理:
- 空间局部性:与被访问的数据相邻的数据很有可能也会被访问。
- 时间局部性:被访问的数据在接下来的时间里很有可能再次被访问。
冲刷dirty buffer:
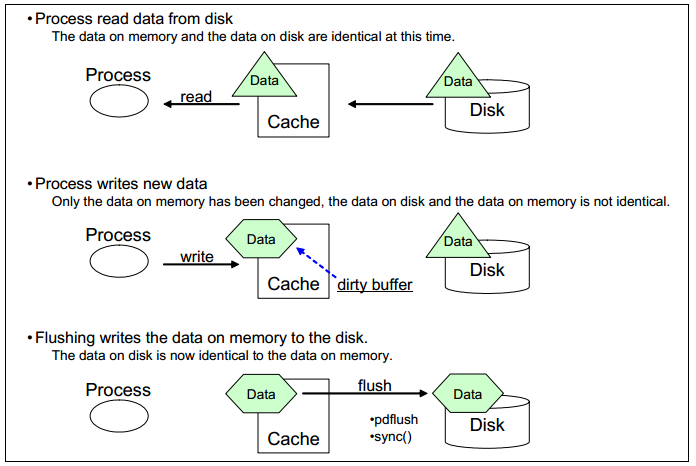
当dirty buffers所占比例超过一个阈值时(在/proc/sys/vm/dirty_background_ratio文件配置),flush操作将会执行。
Block layer
Block layer处理所有与块设备操作相关的任务。其关键的数据结构是bio结构,它是file system layer和block layer之间的接口。
Block size
向驱动读写的最小单位数据,对系统性能有直接影响。作为参考,如果你的服务器处理许多小文件,那么小的block size将会更高效。如果你的服务器处理许多大文件,那么大的block size将会提高性能。Block size只能通过重新格式化才能修改!
I/O elevator
- Completely Fair Queuing (CFQ) : suitable for a wide variety of applications and provides a good compromise between throughput and latency.
- Deadline : excellent request latency and maintains a good disk throughput which is best for disk-intensive database applications.
- Noop : is often the best choice for memory-backed block devices (e.g. ramdisks) and other non-rotational media (flash) where trying to reschedule I/O is a waste of resources
- Anticipatory : was created based on the assumption of a block device with only one physical seek head (for example a single SATA drive).It is an algorithm for scheduling hard disk input/output as well as old scheduler which is replaced by CFQ
RAID和存储系统
####Network子系统
网络的实现
Network layered structure and overview of networking operation:
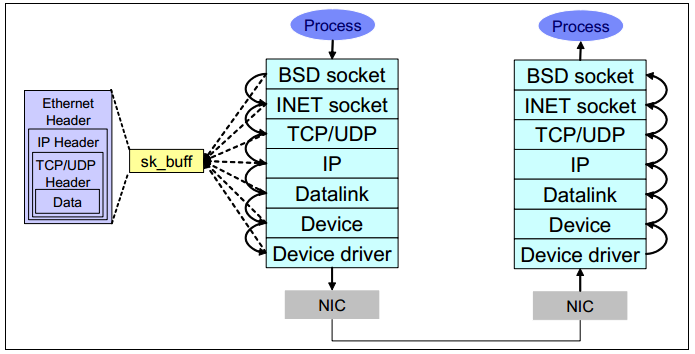
Socket buffer
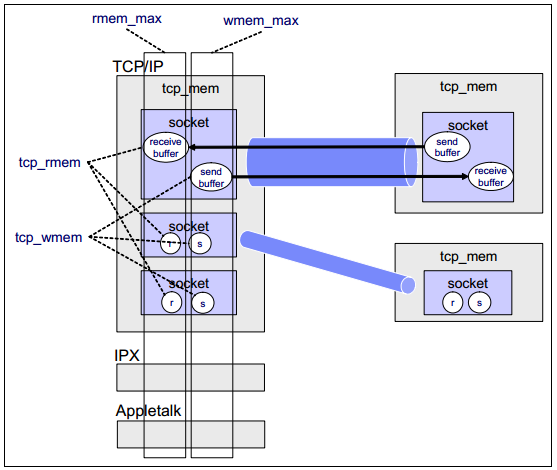
内核使用buffer来发送和接收数据。如下是一些与网络相关的buffer配置:
/proc/sys/net/core/rmem_max /proc/sys/net/core/rmem_default /proc/sys/net/core/wmem_max /proc/sys/net/core/wmem_default /proc/sys/net/ipv4/tcp_mem /proc/sys/net/ipv4/tcp_rmem /proc/sys/net/ipv4/tcp_wmem
Network API(NAPI)
在传统的网络包处理方法上,每当有MAC地址匹配的数据帧到来,就会触发hard interrupt,导致CPU频繁地进行context switch和相应地flush processor cache。
NAPI解决了这个问题,第一个包到达时,跟传统实现类似,会触发一个interrupt。但随后的数据包,network interface将进入polling mode,只要network interface的DMA ring buffer不为空,就不会产生interrupt。当buffer为空时,network interface则进入interrupt mode。
Netfilter
Linux内核有高级防火墙功能,由Netfilter模块提供,可通过iptables修改Netfilter的配置。
通常,Netfilter提供如下功能:
- Packet filtering: 如果一个包匹配某条规则,Netfilter会执行规则定义的操作。
- Address translation: 如果一个包匹配某条规则,Netfilter将会根据地址转换要求修改包。
匹配过滤可以用以下属性定义:
- Network interface
- IP address, IP address range, subnet
- Protocol
- ICMP Type
- Port
- TCP flag
- State
包在Netfilter chains的流动:
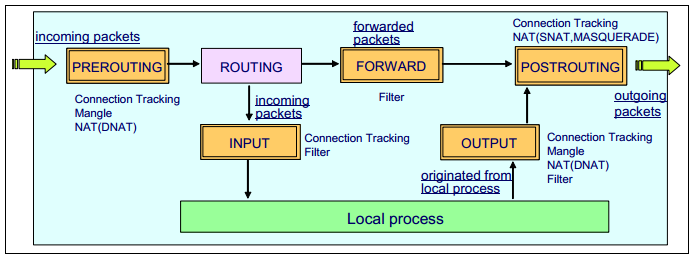
当一个包匹配某条规则时,Netfilter会执行如下可能的target:
- ACCEPT: Accept the packet and let it through.
- DROP: Silently discard the packet.
- REJECT: Discard the packet by sending back the packet such as ICMP port unreachable. TCP reset to originating host.
- MASQUERADE, SNAT, DNAT, REDIRECT: Address translation
Connection tracking
为了取得更加精细的防火墙功能,Netfilter使用connection tracking机制,来跟踪所有的network traffic状态。使用TCP连接状态和其他的网络属性(例如IP address, port, protocol, sequence number, ack number, ICMP type等等),Netfilter将包分为4种状态:
- NEW: packet attempting to establish new connection
- ESTABLISHED: packet goes through established connection
- RELATED: packet which is related to previous packets
- INVALID: packet which is unknown state due to malformed or invalid packet
额外的,Netfilter还能使用其他模块对connection tracking进行详细地跟踪,通过分析协议的属性和操作。例如FTP、NetBIOS、TFTP等。